Building Relic
The idea behind Relic is simple: smart contracts should be able to securely access any data ever pushed to Ethereum. After all, we can easily access the history on Etherscan, or with our own archive node, so why not from dApps?
While the basic idea is simple, there’s a lot that needs to happen to do this in a way that is trustless and secure.
Block Hashes
The first step is getting access to the hashes of every block in the Ethereum chain. On the one hand, this is easy: with about 15.6 million blocks and 32 bytes of Keccak hash per block, that is less than 500MB of data. While that doesn’t sound like a lot of data for 2022, unfortunately Ethereum storage looks and costs a lot less like 2022 storage and a lot more like 1956 storage.

With storage data on Ethereum costing around 20k gas per 32-byte word, it would cost about 6,240 ETH at a gas price of 20gwei to store that much data. That’s probably on par with storing 500MB of data in 1956…
Of course, we have more efficient ways to store the block hashes. Instead of storing them all individually, we can use the ubiquitous Merkle Tree. This data structure uses cryptographic hash functions — functions which take data as input, and output a fixed size blob of data called a hash. Cryptographic hash functions have a few¹ special properties:
- first pre-image resistance: given a hash, it is difficult to find data which results in that specific hash
- collision resistance: it is difficult to create any two different pieces of data which result in the same hash
- second pre-image resistance: given a piece of data, it is difficult to find other data which hashes to the same value (this is a weaker property than collision resistance)
We can combine these hashes into a tree: an arrangement of data where each node has two children nodes associated with it, and the value of a node is the hash of its two children combined. Building this up, each level of the tree has half as many nodes as the level underneath it, until we get to a single root node at the top.
This lets us use only a single cryptographic hash to commit to as much data as we like. Once the top root is fixed, the bottom data leaves cannot be changed. (Because if they could, it would mean someone could bypass one of the stated cryptographic properties of hash functions.)

To prove a particular piece of data is associated with a Merkle Tree, users can present the original data, as well as the sequence of partners that were hashes along side that data as we walk up the tree as a witness. A piece of code like a smart contract can verify that this process results in the correct Merkle root at the end, meaning the data presented must have been present when the Merkle Tree was originally created. There are a few practical constraints², but this effectively solves the storage question: we can take each of our block headers and place them in a Merkle Tree. By storing Merkle roots instead of the entire sequence of data, the storage drops significantly.
Trusting Block Hashes
Of course, it is easy to push a hash on-chain and claim it is correct, but that relies on trust. How will users know that Relic pushed the correct Merkle Tree of block hashes?
Luckily, the entire purpose of blockchains is to make it possible to verify the authenticity of previous data. Each block’s header data is included in the Keccak hash calculation that describes the next block. Similar to a Merkle Tree, this means the current block hash is a commitment to all previous blocks. Therefore, as long as we can link up all of our historic blocks using successive hashing and have the final block match up with the current Ethereum state, we know that all the historic data is correct.

That all sounds great, but how can we take our Merkle Tree and verify successive hashing of all the included data? Unfortunately the answer is: we cannot.
zk-SNARKs
Well okay, that stinks. But what if instead when we create our Merkle Tree, we store some extra information that proves the original data follows the blockchain property? It turns out this is possible using zk-SNARKs. At a basic level, a SNARK³ is a way to use some data to produce a short associated witness (similar to a mathematical proof) that can be used to convince a verifier that the data has certain properties. Intuitively: a SNARK is a way to quickly prove to a third party that a (potentially difficult) computation was done correctly. The magic is that the verification process is very fast, and the associated witness is very small — perfect for the limited resources of the blockchain.
With this, we have all the basic pieces we need to create our historical data. We can “SNARKify” construction of our Merkle Tree to guarantee that the original data has the blockchain property and results in the stated Merkle root. Then we can “connect” the last block in our proof to a recent block that is still accessible from within the Ethereum Virtual Machine (EVM), by showing the recent block was created by hashing the data from our block. Thereby proving that the Merkle Tree was created from our preceding block data.
For practical reasons we do not create a single Merkle Tree for the entire Ethereum history. Instead we make several trees of fixed size. This makes Merkle proofs shorter, and makes it easier to work with as a zk-SNARK⁴, both of these keeping gas costs under control for users.
We’ll talk more about zk-SNARKs and how how Relic uses them more in a future post, but for now this is a good enough overview.
Recent Data
Phew. So now we have handled the historic block hashes, but what if someone needs a block hash from a few hours ago?
First off, Relic maintains a server running 24/7 building zk-SNARK proofs and submitting them on chain once every 8192 blocks (a little under 1 per day).
As we mentioned before, the EVM can access the last 256 block hashes of data, just shy of one hour. But what about the stuff older than 1 hour but newer than 1 day?
Luckily this problem is very similar to the one we solved before with our historical blocks: we would conceptually like to make a hash chain from the desired block to a block recent enough to be accessible from the EVM. As before, rather than attempt to submit hundreds or thousands of blocks and hash them all, the easiest way to do this is to use a SNARK.
Therefore, concurrently with 24/7 building zk-SNARK proofs of Merkle Trees for the block hashes, Relic also sets some aside that are not pushed on-chain automatically. If someone wants to use Relic to prove a fact from 2000 blocks ago, the web2 Relic API will issue their proof as a zk-SNARK of a small Merkle Tree of block headers and their inclusion in that tree, instead of simply an inclusion in one of the already published Merkle Trees.
Ethereum State
At this point we have discussed (at a high level) how to prove any historic block hash on Ethereum. This is already useful in itself for developers⁵ but most people care less about the Keccak hash of a block, and a lot more about what happened inside the block… Luckily this last step is quite straightforward.
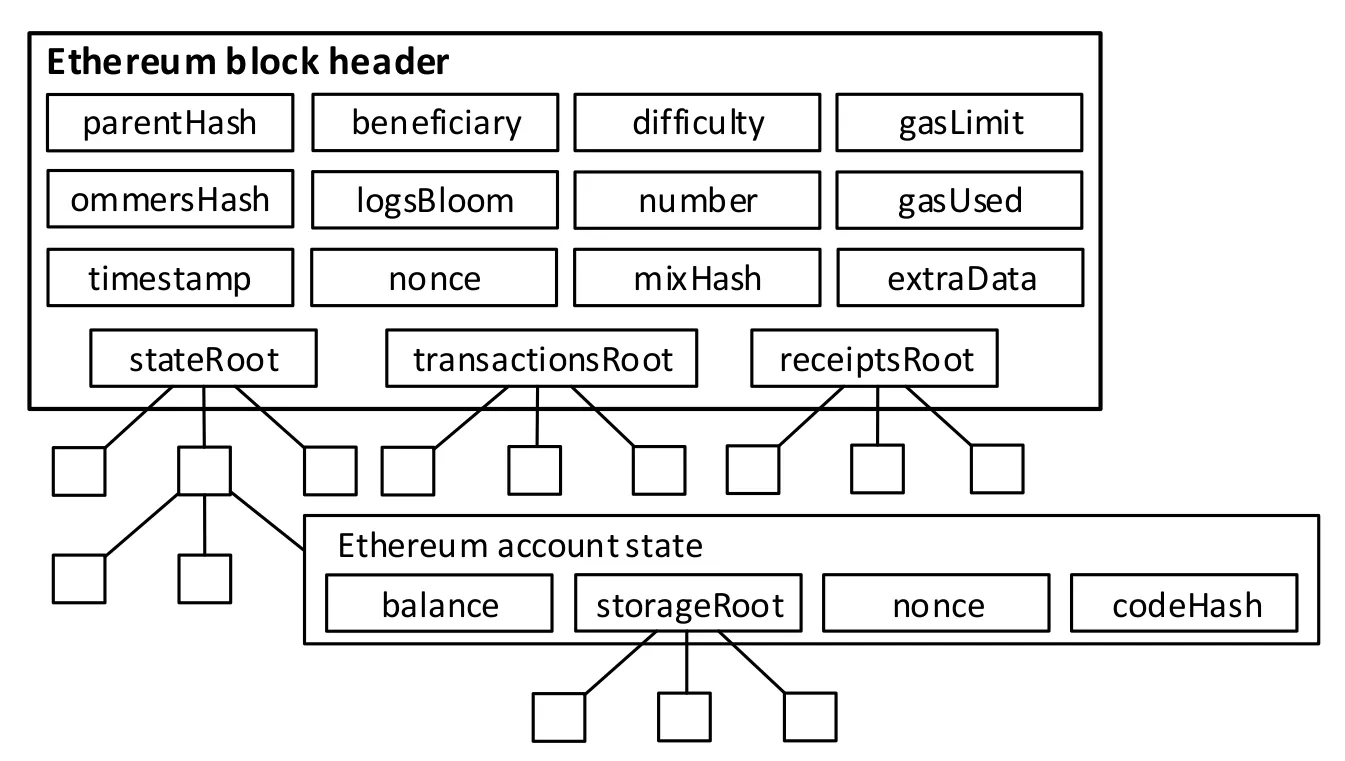
If you’ve been paying attention so far, some of these names should jump out at you. Those things labeled stateRoot, transactionsRoot, receiptsRoot, storageRoot? Those are all roots from Merkle Trees — well technically Merkle Patricia Tries, but it’s the same idea.
If you want to prove a transaction occurred in an Ethereum block: take the block header, extract the transactionsRoot, and then create a Merkle Proof of the transaction. Similarly for other basics in Ethereum (storage, receipts, etc.).
Tying It All Together
This is just an introduction, but you now have the basic idea for how it is possible to access historical data from any point in Ethereum’s history on-chain and in a provably secure way.
Let’s walk through an example of how a user can use Relic to prove a basic fact about historical data, like “my Ethereum account has existed since 2017”⁶.

- Smart contracts which verify zk-SNARKs for block history are deployed by Relic
- The Relic team runs the Relic Prover off-chain to generate proofs of block headers. To make sure the block headers are accurate, they are all verified 100% on chain by the zk-SNARK circuits.
- Users who want to prove their fact (account existed in 2017) can talk to the Relic Prover⁷ off-chain to help construct two proofs: one proving their birth block existed in the Ethereum chain (by showing it exists in the Merkle Tree of proven block hashes, or showing it is in the last 256 blocks, or using a SNARK), and another proof showing the Ethereum
stateRootMerkle Patricia Tree has an entry for their account in that block. - These two proofs are then submitted to the State Proof Verifier which ensures both proofs are correct.
- The State Proof Verifier then stores the proven fact in the Reliquary⁸, to commit the fact to the blockchain for future use (without requiring proofs each time).
- For things like Birth Certificates, a Soul Bound Token⁹ may be issued, so users get to show off their proven facts on OpenSea or similar places.
Once a fact is proven, it can easily be queried fully on-chain by any dApp by interacting with the Reliquary. Any smart contract can now easily verify facts about Ethereum state at any point in the history of the entire chain!
Stay Tuned
We hope you enjoyed learning about how Relic works! Keep track of our project on Twitter and Discord as we publish more information. Read our code in depth on our Github, and try Relic for yourself at https://app.relicprotocol.com/.
Check back for more in-depth posts about how we use zk-SNARKs, how Relic can be used by dApps, and more!
[1] There are other properties important for general use, but less important here.
[2] The size of the witness data is logarithmic in the length of the data stored. For a tree of about 16 million items, that would be 24 hashes that need to be presented in call data as a witness. This also does not allow for easy updating of the Merkle Tree as new blocks are produced.
[3] While zk-SNARKs are a special type of SNARK that provides additional privacy guarantees called “zero knowledge”, this is not important for our use case. Modern SNARKs happen to be zk-SNARKs as well, but this need not be the case.
[4] The time (and thus gas) to verify a SNARK still grow with the amount of “stuff” (called circuit size) you want to verify. Additionally, while it is fast to verify a SNARK, it is quite difficult to create them — and again the cost to build SNARKs scales with its size.
[5] You can access this data today from our contracts! Though we are still working to improve the documentation of these features.
[6] We call this a “Birth Certificate”, you can make your own at https://app.relicprotocol.com/
[7] Today it is easiest to use the Relic Prover to create this, but it is not required!
[8] A reliquary is a container for relics.
[9] Why not a transferable NFT? If Birth Certificates (or other facts) were transferable, they would have no meaning!
